Simple Website Analytics Using CaddyServer Logs
Simple Caddy and Hugo Analytics
I previously discussed my recent change towards digital minimalism and as part of that transition, I moved towards a static website and removed any external services that I felt weren’t adding value. I also wanted to get some sort of basic analytics, but all the solutions I found were adding unnecessary bloat and for my use case, I didn’t need anything too fancy since I don’t use that analytics information to sell you something or target content. With that in mind I decided to develop a small console application that parses the Caddy server logs generated by this page and outputs the result to the console.
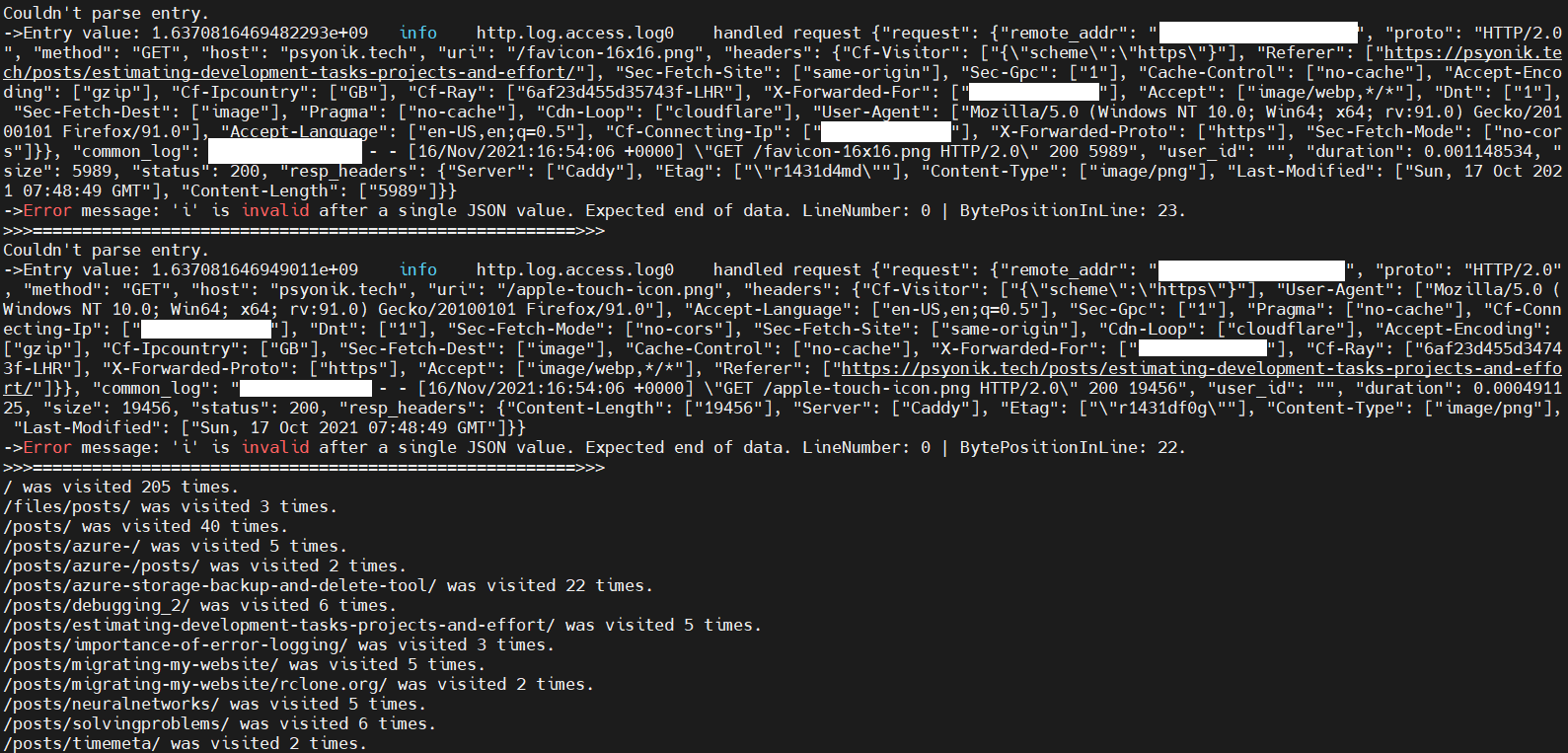
Screenshot of the “analytics” output after running the application
Why Build Another Log Parser
Before digging into the why, for those interested in trying it out, you can find it on my Gitlab account. The source code itself is there and it’s less than 90 lines of code including spaces, comments with a column width of 100.
I wanted to get information on what URLs on my page are visited and how often. The page is running behind Cloudflare and they provide analytics, but these don’t show (as far as I know) the actual URLs visited. Also, I was sure that a good part of those visitors are just people trying to gain access to the website by spamming known entry points to most common personal websites. A quick dig into my Caddy logs revealed as much - wp-login or variations of wp-*** were littering my logs. This meant that the analytics provided in Cloudflare will show incorrect visitor counts.
The next issue was the fact that the logs are formatted as JSON and a variety of different log parsing tools out there for Linux do not parse JSON that well or they simply do not support JSON formatted log entries or they add another application that I need to install and learn how to use. For those looking for other log analysers, I would probably recommend lnav, logwatch, multitail or Splunk.
With this in mind, this application should be easy to use, the output should come out formatted and it should be easily deployable with minimal dependencies.
Console Caddy Log Parser Overview
As I currently work as a .Net developer, I decided to use C# and write the parser as a console application. It only uses the built in .Net libraries, there are no external libraries or configurations you need to do. It doesn’t require special permissions and it Just Works (TM).
The app serves as the basis for a larger application I’m building, capable of converting Caddy server logs into actual objects that can be manipulated easily. That application is currently a work in progress, but I might update the article once it’s done. In any case, allow me to go over the structure of the app so that if you do decide to use it, you can make changes or adjust it to your needs. If it ticks all the right boxes for your personal setup, then you could probably just clone it and run it.
The application starts off in Program.cs and it reads the string command line argument that represents the whole path to the Caddy log file you wish to parse:
using System;
using System.Threading.Tasks;
namespace consolecaddyparser
{
class Program
{
static async Task Main(string[] args)
{
string logFilePath = args.Length > 0 ? args[0] : "";
if (logFilePath.Equals(""))
{
Console.WriteLine("You have not provided anything as a command line argument.\n"
+ "Run the application with `dotnet run /caddy/server/logFile/path`");
}
else
{
var results = await CaddyFileReader.DisplayUris(logFilePath);
if (results != null)
{
foreach (var uri in results)
{
string time = uri.Value == 1 ? " time." : " times.";
Console.WriteLine(uri.Key + " was visited " + uri.Value + time);
}
}
}
}
}
}
There is a basic guard, so that if not argument is passed in, a helpful error message should inform you how the command needs to be ran. The next step passes on the path to the CaddyFileReader static class, which will then return a SortedDictionary<string, int>. The dictionary will hold the Uri that was accessed along with the number of times that particular Uri shows up in the log file. Realistically, you could have the same user who visits the same Uri several times, but this is just to get a rough idea of how many people reach your links on average.
The next portion represents the first part of the file reader class. The entire class can be viewed in the repo, this is just the first bit inside the DisplayUris method.
List<string> fileContents = new List<string>();
SortedDictionary<string, int> visitors = new SortedDictionary<string, int>();
await Task.Run(async () =>
{
// read the log file on the given path and save values into a list of strings
await using (FileStream SourceStream = File.Open(
filePath,
FileMode.Open,
FileAccess.Read,
FileShare.ReadWrite))
{
try
{
byte[] logFileContents = new byte[SourceStream.Length];
await SourceStream.ReadAsync(logFileContents, 0, (int)SourceStream.Length);
fileContents = System.Text.Encoding.ASCII.GetString(logFileContents)
.Trim()
.Split('\n')
.ToList();
}
catch (Exception ex)
{
System.Console.WriteLine($"Something went wrong reading the log file! - {ex.Message}");
}
}
A list of strings is created and a new dictionary. Next, the file contents are read and the file at this point should remain accessible and readable/writeable despite this console app reading its contents. The contents are used to populate a byte array and then the byte array gets encoded into a string which is split up based on each new line.
The goal here is to end up with a list of strings, each string representing a JSON object. If anything goes wrong, you should get an error message here and if there is a problem, at this point it would only be strictly an “environmental” issue, so as long as the file is where it’s supposed to be and the path is correct, there shouldn’t be any particular issue here.
The next portion represents the bottom part of the class which will be responsible for converting the list of strings representing JSON objects into the dictionary that gets returned.
// Parse strings in list and get URIs and IP count that visited the URI
foreach (var row in fileContents)
{
try
{
using (JsonDocument document = JsonDocument.Parse(row))
{
JsonElement root = document.RootElement;
JsonElement requestElement = root.GetProperty("request");
JsonElement uriElement = requestElement.GetProperty("uri");
var uri = uriElement.GetString();
// all useful URLs on my page end with '/' so this weeds out all the spam
if (uri.EndsWith("/"))
{
if (!visitors.ContainsKey(uri) && uri.Length == 1
|| !visitors.ContainsKey(uri) && uri.Contains("posts"))
{
// a bit hacky and unreliable - what if this pattern changes?
string uriToFind = $"\"uri\":\"{uri}\"";
visitors.Add(
uri,
fileContents.Count(x => x.Contains(uriToFind))
);
}
}
}
}
catch (Exception e)
{
System.Console.WriteLine($"Couldn't parse entry." +
$"\n->Entry value: {row} " +
$"\n->Error message: {e.Message}" +
$"\n>>>=======================================================>>>");
}
}
});
return visitors;
The above code uses JsonDocument to parse a string from the list into an actual Json object which allows me to access properties. The properties that are important here are the request and the uri properties. Because of the URLs generated by Hugo end with / I filter out all results on that first of all. Then, I check if the dictionary of visitors already contains that uri and if it doesn’t and it has a length of 1 (the root of the website) or it contains the word posts, I search the URI inside the list of strings and return the number of times it shows up.
This feels very inefficient, because it is, however, the goal of this is to stay as simple as possible. I will probably spend some time next to improve the process of searching so as to reduce the time spent looking for matches. Recursion might be a good option here, whereby the list gets entries removed when they have already been counted once and then passed in again into a method that searches for the count of Uris. If I will have some time over the next few days/weeks I will definitely revisit it since it is a bit slow on the 1 core 1 GB of RAM VPS that runs this website.
Alternatives and What’s Next
The first thing I will want to improve is the performance of the search portion.It is on the slow side, so I’ll spend more than an hour to review it and maybe improve this a little. Once I do that, I will be updating the article and the repo, but this should work in the meantime.
If you want more detailed analytics, I would probably recommend Plausible, Simple Analytics or Matomo in no particular order. I haven’t personally tried any of them, but based on the reviews and their business model, they seem to offer the best balance between privacy, analytics and ease of use.
Next up I plan on writing a guide to guide you in setting up a static Hugo website (like this one), customize it and host it for free. There is a refreshing aspect about being able to customize your own corner of the Internet in a world where we’re constantly forced to map ourselves to social networks and the discrete elements they define as important.